Markov Chain Monte Carlo
Markov Chain Monte Carlo (MCMC) methods are a class of algorithms designed for exact sampling from a target probability distribution $P$ defined on a measurable space $(\mathcal X, \Sigma)$. They achieve this by constructing a Markov chain $\left\{X_\mu\right\}_{\mu=1}^{M}$ that has $P$ as its equilibrium distribution. These methods are particularly useful when direct sampling is difficult. Once the chain has been constructed, the expected value of any quantity $\mathcal A$ can be estimated as the empirical average
\[\mathbb E_P\left[\mathcal A\left(x\right)\right]=\lim_{M\to+\infty}\sum_{\mu=1}^{M}\mathcal A\left(X_\mu\right).\]
Building such a chain requires specifying a transition kernel $K\left(x,X'\right)$, which quantifies the conditional probability for transitioning from state $x\in\mathcal X$ to any state $x'\in X'\subseteq\Sigma$. A sufficient condition for sampling the correct target distribution is that $K$ satisfies the detailed balance relation
\[P\left(\mathrm dx\right)K\left(x,\mathrm dx'\right)=P\left(\mathrm dx'\right)K\left(x',\mathrm dx\right).\]
The Metropolis-Hastings Algorithm
The Metropolis-Hastings (MH) algorithm is one of the most widely used MCMC methods. It works by separating the transition kernel $K$ into a proposal and acceptance step:
- Starting from the current state $x$, a new state $x'$ is drawn from the proposal distribution $Q\left(x,X'\right)$.
- The transition is accepted with probability
\[\alpha\left(x,x'\right)=\min\left\{1,\,\frac{P\left(\mathrm dx'\right)Q\left(x',\mathrm{d}x\right)}{P\left(\mathrm dx\right)Q\left(x,\mathrm{d}x'\right)}\right\}\]
and rejected with probability $1-\alpha\left(x,x'\right)$. Provided that the proposal distribution $Q$ guarantees ergodicity, the condition of detailed balance ensures that the MH algorithm eventually samples the desired distribution $P$.
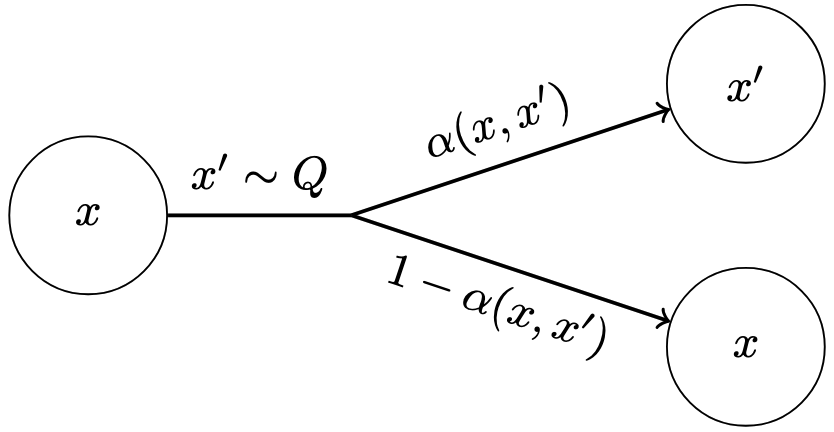
Schematic representation of the Metropolis-Hastings algorithm.
Implementation in Arianna
In Arianna, the Metropolis-Hastings algorithm is implemented through the Metropolis struct, which requires:
- A system state representation
- A pool of Monte Carlo moves (actions)
- Proposal distributions (policies) for generating new states
- Functions to calculate:
- The log target density (
unnormalised_log_target_density) - The log proposal density (
log_proposal_density) - How to sample an action (
sample_action!) - How to perform actions (
perform_action!)
- The log target density (
See the Adding Your Own System section for details on implementing these components for your specific problem.